
|
|
CPU和GPU的区别
简介
CPU的主要功能是解释计算机指令以及处理计算机软件中的数据。
GPU是图形系统结构的重要元件,是连接计算机和显示终端的纽带。
GPU的发展
光栅化显示系统离不开图形处理器。早期的显卡只包含简单的存储器和帧缓冲区,它们实际上只起了一个图形的存储和传递作用,一切操作都必须由CPU来控制。
这对于文本和一些简单的图形来说是足够的,但是当要处理复杂场景特别是一些真实感的三维场景,单靠这种系统是无法完成任务的。 所以后来发展的显卡都有图形处理的功能。它不单单存储图形,而且能完成大部分图形功能,这样就大大减轻了CPU的负担,提高了显示能力和显示速度。
主要区别列表
|参数| CPU | GPU | | – | – | |通用性|通用|专用| |核心数|少|超级多| | 线程数 | 少 | 多 | | reg数 | 少 | 多 | | cache容量 | 大 | 小(计算卡的也不小)| | SIMD | 小 | 大 | | 时钟频率 | 较高 | 较低 | | 运算延迟 | 相对较小 | 相对较大 | | 数据吞吐量 | 相对较小 | 相对较大 | |功耗|相对较低|相对较高| |单核心任务复杂程度|复杂|简单| | 任务调度 | 通过操作系统调度 | 无复杂调度 | | 控制逻辑 | 复杂 | 简单 | | 优化电路 | 相对复杂 | 相对简单 |
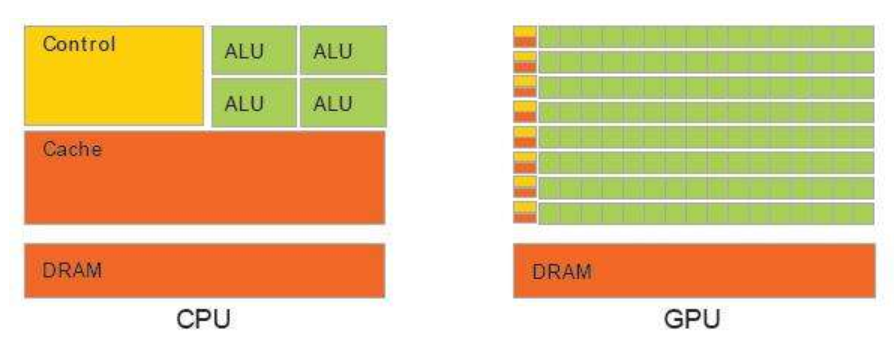
- CPU需要很强的通用性来处理各种不同的数据类型,同时又要逻辑判断又会引入大量的分支跳转和中断的处理。这些都使得CPU的内部结构异常复杂。
- GPU面对的则是类型高度统一的、相互无依赖的大规模数据和不需要被打断的纯净的计算环境。
综上所述:
- CPU被设计用于执行各种不同类型和级别的串行任务,包括操作系统运行、应用程序执行、数据处理等,适用于广泛的计算任务。
- GPU包含大量小而高效、能同时处理多个相似任务的核心,最初设计用于图形渲染,在不断发展的过程中向着并行处理而优化。这种并行性使GPU适合处理大规模数据集,执行相同计算的多个任务。
- GPU的计算速度比CPU快得多?emm,GPU相对于CPU的速度取决于执行的计算类型。
为什么GPU适合炼丹
一、并行处理优势
图形卷积计算的filter是一个接一个地依次进行、每次计算独立于其他计算的。
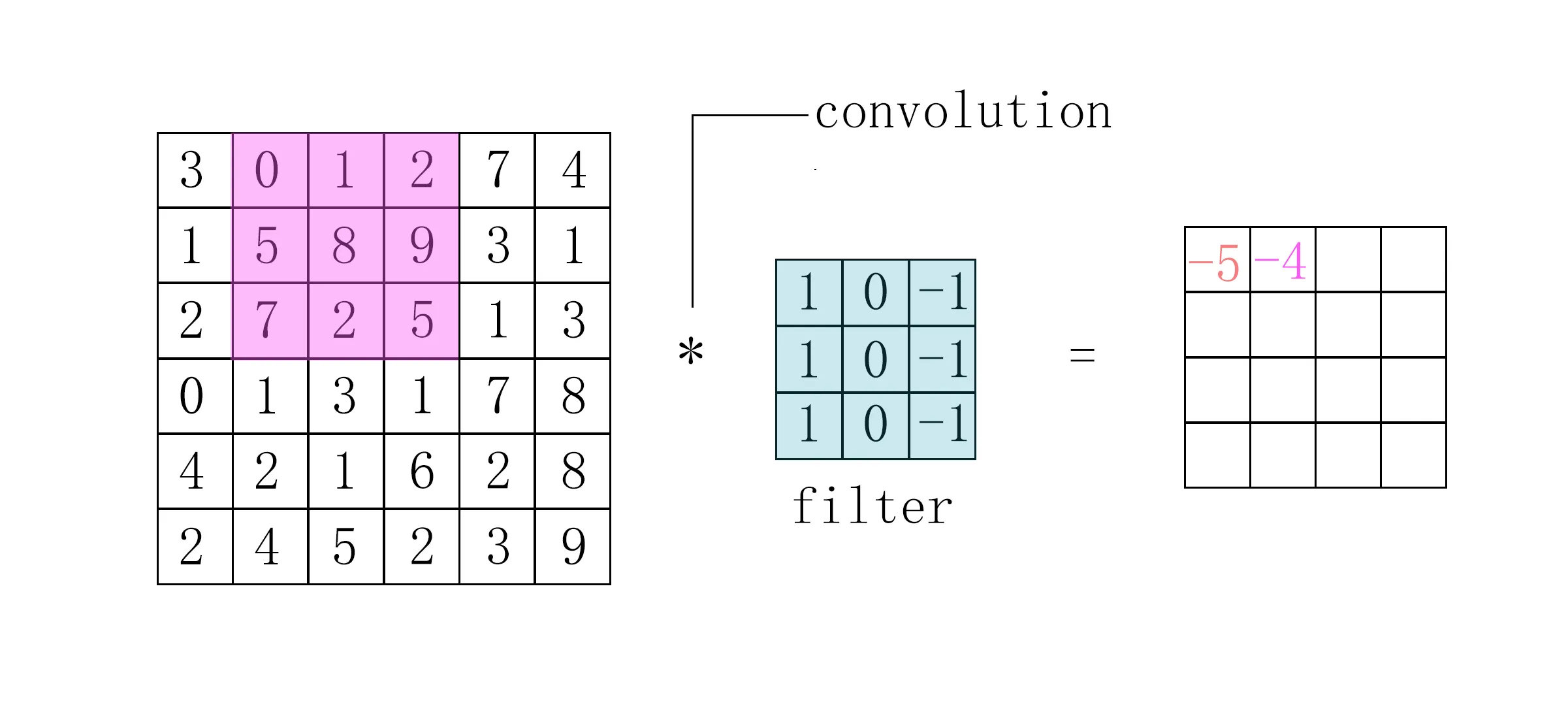
因此卷积神经网络的许多计算都可以分解成更小的计算单元,且小的计算集不会相互依赖,它是高度并行的。

GPU在机器学习领域大展身手的原因也是跟他们的特点有关。机器学习任务通常牵涉到大规模数据并行计算,而GPU高并行性使得它们在处理并行计算任务时表现卓越。
二、浮点计算优势
浮点运算的结果不是准确值,它的精度取决于数据位宽。 要解决精度问题,也只能提高位宽。
计算单元位宽
实际使用的单精度浮点是32位,双精度是64位。 CPU的FPU率先支持了更高宽度的数据。英特尔的CPU计算浮点的时候内部精度是80位,输出输入还是64位;但很多GPU(一般Nvidia非专业卡现在都给蔽了双精度)都是单精度32位的,专业计算卡现在一般都是64位。
CPU和GPU浮点运算性能比较
CPU的FPU和逻辑单元、核心数量和频率都是同步的。每个FPU必须配对全套的逻辑和编解码单元以保证编程方面的兼容性。这也许也是就限制了CPU的核心做不了太多的一个因素。 反正核心就那么几个,只能把CPU单核频率上升到很高的水平,支持各种超级宽的数据格式。
而相比之下,GPU就是大批大批的小型FPU,其他的东西能少就少。 GPU擅长的是数值计算,不擅长处理分支和随机读写。
如果只做一道浮点运算,其实是CPU更快(频率更高嘛)。
但问题的关键是,通常来说浮点运算都是大批量的任务且互相之间没有关联。这种情况下,复杂的浮点运算就变成一个并行问题了(和第一个原因有所重合),GPU大批量低频小FPU就有显著优势了(一言以蔽之,堆料也)。
综上所述,GPU浮点运算能力得到充分发挥的前提是:
- 任务向量化
- 连续读写
- 任务分支少
而神经网络就是一个这样的模型。
三、Nvidia的努力
是的没错,Nvidia的不断努力也是GPU适合神经网络的重要原因。 Nvidia想方设法让GPU突破传统,装载更多先进的单元以应对更复杂的任务。没有Nivida,GPU最起码不会这么适配神经网络计算。
其中比较有代表性的就是张量计算核心TC。 矩阵运算和张量运算是TC加速的主要对象,
- 硬件加速:与传统的GPU相比,TC是专门设计用于数学计算的硬件,因此在执行矩阵和张量运算时具有显著的加速效果。这使得GPU成为深度学习任务的理想选择。
- 资源优化:GPU中的资源分配对性能至关重要。在一个流式多处理器(SM)中,拥有TC能大大降低共享内存访问和FFMA操作的成本,让每个线程专注于更多的计算,而不是计算索引。
在深度学习中的应用在深度学习中,TC的应用广泛,包括矩阵乘法、卷积运算、元素级操作以及其他数学运算。这些操作构成了深度学习模型的基础,而TC的高性能和并行计算能力有助于加速训练和推理过程。
四、生态支持
GPU得到了TensorFlow、PyTorch等主流深度学习框架的良好支持,这使得开发者可以很方便地使用GPU进行深度学习的开发。
这确实很重要。之前苹果联盟了Pytorch,然后发现M3芯片的笔记本跑Stable Difussion比以前快的不是一个档次,比大部分显卡都快。。。
总结:什么类型的程序适合在GPU上运行?
- 易映射并行
- 计算密集型
- 任务向量化
- 随机读写少
- 任务分支少